
CodeSignalは、複数のAIモデルのソフトウェアエンジニアリング能力を比較したベンチマーキングレポートを発表しました。CodeSignalは企業に技術者採用プラットフォームを提供する米国の企業です。
レポートによると、OpenAIのo1-previewとo1-miniが総合スコアと解決率で最高のパフォーマンスを示しました。また、GPT-4oは完璧な解答を作成する能力に優れ、Sonnetは単純な問題で良い結果を出しています。
AIモデルと人間を比較すると、トップクラスの人間候補者は依然として全てのAIモデルを上回っていますが、ほとんどのAIモデルは平均的な候補者よりも優れたパフォーマンスを示しました。
ただ、o1シリーズはトップクラスの候補者にかなり肉薄していて差はわずかになってきています。また、o1だけでなくClaudeなどのモデルも平均的な候補者よりはるかに良いスコアを出しています。
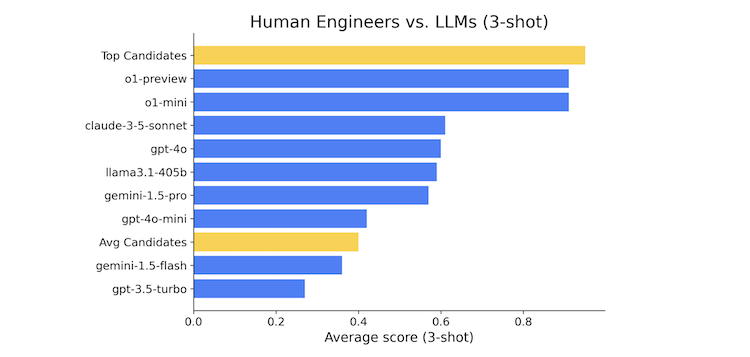
レポートでは、AIモデルは効率的にコーディングタスクを処理しますが、複雑な問題となると、まだ人間の直感や創造性が重要となってくる、と結論付けています。
この結論を言葉通り受け取って良いのであれば(あまりのショッキングな結果をフォローするだけの発言ではない、とすれば)、人間は直感や創造性のところを担い、あとはAIモデルに任せる、というチーム構成が現状では良さそうです。

