
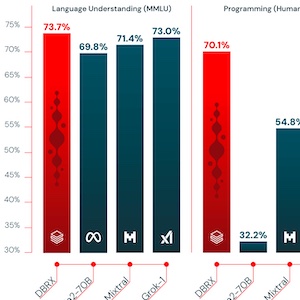
データとAIを扱う企業のDatabricksが、このほど新しいオープンソースの大規模言語モデル「DBRX」を発表しました。DBRXは、言語理解、プログラミング、数学の分野において、Mixtral 、Llama-2 70B、Grok-1など、主要なオープンソースモデルを上回る性能を達成しています。
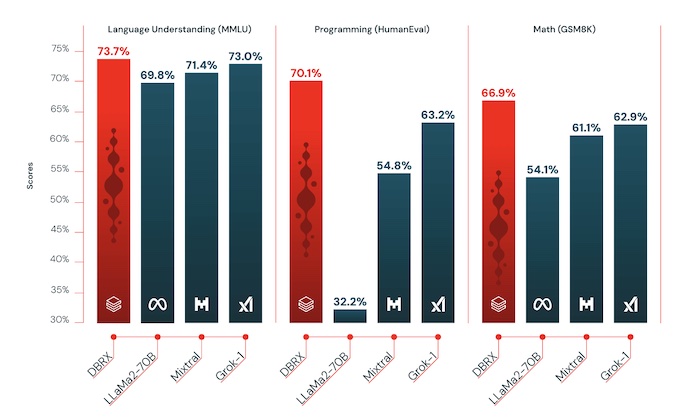
Image Source: Capture from Databricks
DBRXは、1320億ものパラメータを持つ「mixture-of-experts(MoE)」と呼ばれるアーキテクチャを採用しています。これは、生成される単語ごとに、必要なパラメータの一部だけを活性化させることで、効率性を高め、コストを抑えることができる仕組みです。その結果、推論速度はLLaMA2-70Bの最大2倍、パラメータ数はGrok-1の約40%に抑えられています。
驚くべきことに、DBRXの学習には、わずか1000万ドル(約15億円)と2ヶ月しかかかっていないとのことです。これは、AI業界に新しい基準を打ち立てるものといえるでしょう。ただし、今回の xAIの「Grok 1.5」の発表や、Metaが近々発表予定の「Llama 3」など、他社も今後次々とアップグレードを発表してくることを考えると、DBRXがオープンソースモデルのトップの座を維持し続けるのは難しいかもしれません。
Databricksは、Apache Spark™、Delta Lake、MLflowの生みの親として知られる企業で、大量のデータを扱うことを得意としており、世界で初めてクラウド上でレイクハウスプラットフォーム(*)を提供しています。同社は、データとAIをより身近で使いやすいものにすることを目指し、世界中の9,000以上の組織に高度なデータ分析ソリューションを提供しています。元々大量の整理されたデータを扱うことを得意としているため、AIのトレーニングデータの作成やトレーニングそのものにそうした知見が生かされているものと思われます。
DBRXは、GitHubとHugging Faceを通じて無料で利用でき、研究者や企業が自由に活用することができます。Databricksは、LLMをオープンソースにすることで、自社の技術の優位性を対外的に示すとともに、AI研究の裾野を広げ、コミュニティのイノベーションを促進しようとしています。
*大量のデータを処理しやすい形で保管するプラットフォームの意(データレイクとデータウェアハウスの合成語)


