

Meta が公開した Llama 4 Maverick の未修正版が、AI モデルの性能を比較するプラットフォーム「LMArena」において、予想を下回る結果となっています。当初 Meta は特別に最適化された実験バージョン「Llama-4-Maverick-03-26-Experimental」が ELO スコア 1417 を獲得し、GPT-4o を上回り Gemini 2.5 Pro に次ぐ 2 位にランクインしたと発表しました。しかし、一般公開されたバージョン「Llama-4-Maverick-17B-128E-Instruct」が評価されると、なんと 32 位まで順位を落としています。
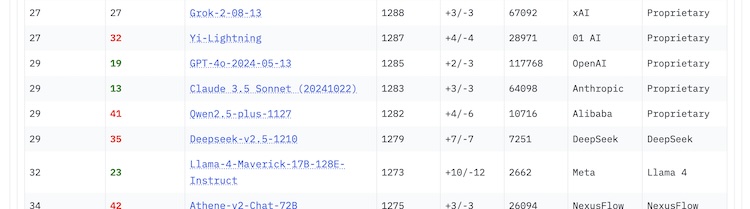
Llama 4 Maverick は、17B(170 億)のアクティブパラメータと 128 の専門家(experts)を持つ大規模言語モデルで、テキスト処理、推論、マルチモーダルタスクなど幅広い用途に対応することを目指しています。Meta はこれが OpenAI の GPT-4o や Google の Gemini 2.0 Flash に匹敵する性能を持つと主張していました。
しかし実際の評価では、2024 年 9 月にリリースされた Google の Gemini 1.5 Pro や 2024 年 6 月にリリースされた Anthropic の Claude 3.5 Sonnet といった数か月前のモデルにも劣る結果となりました。特に LMArena の「Style Control」機能を使用すると、Maverick の順位はさらに下がるケースも報告されています。
この問題の核心は、Meta がベンチマークで高得点を取るためだけに特別に最適化したモデルをリリースしたのではないか、という点にあります。AI コミュニティからは「ベンチマーク最適化は実世界の性能を反映しない」との批判が上がり、透明性の欠如が問題視されました。これに対し Meta の生成 AI 担当副社長 Ahmad Al-Dahle 氏は「(ベンチマークの)テストセットでトレーニングしたという主張は事実ではない」と反論し、性能のバラつきは「実装の安定化の問題」に起因すると説明しています。
LMArena 側も「Meta のポリシー解釈が我々の期待と一致しなかった」として、ベンチマークの公平性を保つため、モデル提供者に対し公開バージョンの使用を明確に求める新ルールを導入しました。
この一件は、Meta の AI 開発における透明性と信頼性に疑問を投げかける結果となり、オープンソースモデルとして広く受け入れられてきた Llama シリーズのブランドイメージにも影響を与える可能性があります。Meta は今後、開発中の Llama 4 Behemoth(約 2T パラメータ)のリリースで巻き返しを図ると見られますが、コミュニティの信頼回復には透明性の向上が不可欠となりそうです。


